火山引擎DataLeap在数据血缘的一些更新特性
-
超级管理员

- 2023-09-18 09:54:09
- 超级管理员
DataLeap是火山引擎数智平台VeDI旗下的大数据研发治理套件产品,帮助用户快速完成数据集成、开发、运维、治理、资产、安全等全套数据中台建设,降低工作成本和数据维护成本、挖掘数据价值、为企业决策提供数据支撑。
数据血缘是帮助用户找数据、理解数据以及使数据发挥价值的基础能力。基于字节跳动内部沉淀的数据治理经验,火山引擎DataLeap具备完备的数据血缘能力,本文主要讲述火山引擎DataLeap的一些更新特性。
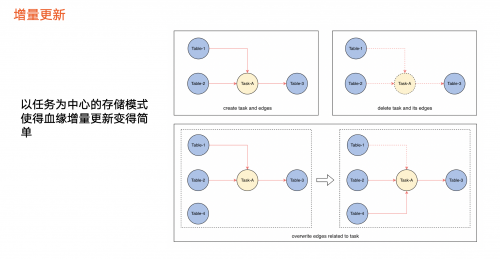
增量更新
(图:增量更新)
在实时血缘基础上,火山引擎DataLeap还支持增量更新能力,即当某一个任务的加工逻辑发生变化时,只需要更新图中一小部分。
●血缘创建:数据加工逻辑上线或开始生效,将被抽象为图数据库的操作,即创建一个任务节点和对应的数据节点,并创建两者之间的边。上图例子为表1、表2和任务的边,以及任务和表3之间的边。
●血缘删除:数据的加工逻辑发生了下线、删除或不生效。先在图里面查询该任务节点,把任务节点以及关联血缘相关的边删除。血缘存储模型以任务为中心,因此表1、表2和表3之间的血缘关系也同步消失,这部分血缘即被删除。
●血缘更新:任务本身没有发生上线或下线,但计算逻辑发生变化。例如,原本血缘关系是表1、表2生成表3,现在变成了表2、表4生成表3。我们需要做的如下:
○解析出最新血缘状态,即表2、表4到表3的血缘关系,与当前血缘状态做对比(主要对比该任务 a 相关的边),上图例子是入边发生变化,那么删除其中一条边,构建另外一条边,即可完成该任务节点的血缘更新。
○如果面临以上血缘关系变化,但是没有该任务节点,应该执行哪些操作来更新血缘?由于只有血缘最新状态和当前状态,没有任务节点去获取最小单位的血缘关系,所以只能进行全量血缘或全图对比,才能得出边的变化情况,再更新到图数据库中。如果不进行全量血缘或全图对比,无法知晓如何删除条和创建条,导致血缘无法更新。这也是前两个版本需要进行血缘快照对比的原因。
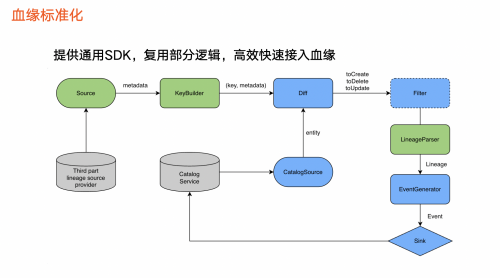
(图:血缘标准化)
在火山引擎DataLeap中,通常把血缘数据接入抽象成一个 ETL 。
首先,血缘数据来源,即第三方平台血缘相关的数据,通常是一个数据加工逻辑或者称为任务。接着,对这些任务完成 KeyBy 操作,并与数据资产平台的任务信息做对比,确定如何进行任何创建、删除和更新。
在再完成过滤操作之后, 由Lineage Parser 对创建、更新等任务进行血缘解析,得出血缘结果之后会生成表示图相关操作的Event,最终通过Sink 把数据写入到数据资产平台中。
上图绿色和蓝色分别表示:
●蓝色:对不同血缘接入过程的逻辑一致,可抽象出来并复用。
●绿色:不同血缘的实现情况不一样。例如,某一个平台为拉取数据,另外一个平台通过其他方式获取数据,导致三个部分不一样,因此我们抽取特殊部分,复用共同部分。除此之外,我们还提供通用 SDK,串联整个血缘接入流程,使得接入新的血缘时,只需要实现绿色组件。
目前,字节跳动内部业务已经可以使用 SDK 轻松接入血缘。
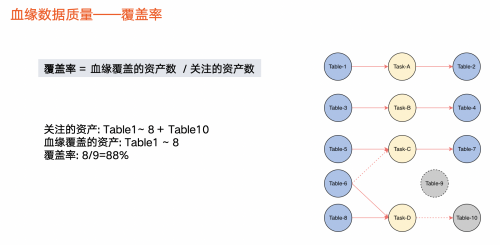
(图:数据血缘质量-覆盖率)
当血缘发展到一定阶段,业务方不止关心血缘覆盖情况、支持情况,还关心血缘数据质量情况。因此,第三版本透出血缘质量相关指标——覆盖率和准确率。
覆盖率:血缘覆盖的数据资产数占关注的资产数量占比。
关注的数据资产一般指,有生产任务或有生产行为的资产。上图虚线圆圈,如 Table 9,用户创建该表后没有生产行为,因此也不会产生血缘,在计算中将被剔除掉。上图实线圆圈,表示有生产行为或有任务读取,则被认为是关注的资产。关注的数据资产被血缘覆盖的占比,即覆盖率。
以上图为例,在10张表中,由于有任务与Table 1 ~ 8关联,因此判定有血缘。 Table 10,它与Task-D之间的连线是虚线,表示本来它应该有血缘,但是实际上血缘任务没把这个血缘关系解析出来,那么我们就认为这个 Table 10是没有被血缘覆盖的。整体上被血缘覆盖的资产就是表1 ~ 8。除了Table 9之外,其他的都是关注的资产,那么血缘覆盖的资产占比就是8/9。也就是图上蓝色的这第8个除以蓝色的8个加上 Table 10,就是9个,所以这个覆盖率就是88%。
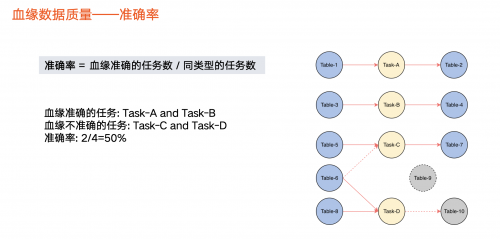
(图:数据血缘质量-准确率)
覆盖血缘不一定是正确的,所以我们还定义了准确率指标,即血缘准确的任务数/同类型的任务数。
举个例子,假设任务 c的血缘应该是 Table 5、Table6生成 Table 7,但实际上被遗漏,没有被解析(虚线表示),导致任务 c 的血缘不准确。也存在其他情况缺失或多余情况,导致血缘不准确。
在上图中,同类型任务包含4个,即 a、b、c、d。那么,准确的血缘解析只有 a、b,因此准确率占比为2/4 = 50%。
在火山引擎DataLeap中,由于血缘来源是任务,因此我们以任务的视角来看待血缘准确率。
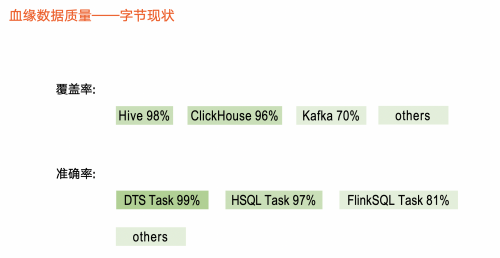
(图:血缘质量-字节现状)
在覆盖率部分,目前 Hive 和 ClickHouse 元数据覆盖度较高,分别达到98%、96%。对于实时元数据,如Kafka ,相关 Topic覆盖70%,其他元数据则稍低。
在准确率部分,我们区分任务类型做准确性解析。如 DTS 数据集成任务达到99%以上,Hive SQL 任务、 Flink SQL 任务是97%、81% 左右。



_20241123170632_743.jpg)






{kind=link}