打通AI的任督二脉 TE Connectivity搭建224G智慧互连
-
超级管理员

- 2024-09-06 17:22:14
- 超级管理员
随着AI领域正经历如火如荼的发展,无论是NVIDIA收购Mellanox,还是AMD收购Pensando,以及AWS的Nitro DPU加速卡,都旨在加强数据中心及AI集群计算应用中,数据加速、网络优化、安全防护等相关计算任务的加速处理,即增强连接能力。

而在这个市场中,还有多位隐形大佬,其产品技术不仅仅是为自家的解决方案提供服务,更以技术和功能上通用的优势,为开放市场产品提供芯片高性能互连层面的能力加持。
集群计算首次就高速网络提出了高要求,众厂商纷纷寻求摆脱以太网络、铜缆束缚的光纤及新网络技术,56G、112G技术纷纷突破,超越了25G的背板连接速度瓶颈。AI时代的到来,对芯片、系统、主机以及机柜间互连能力提出了更高的要求。在大数据时代,巨量的单向、点对点、低频度数据传输逐渐向双向、多点、高频度海量传输模式转变。
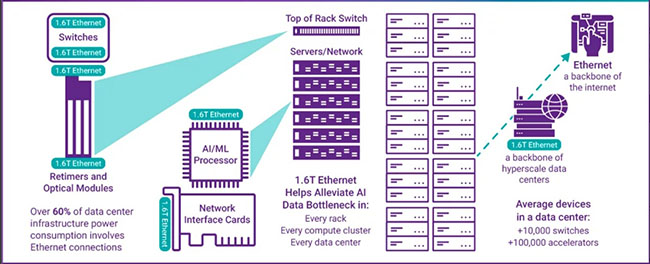
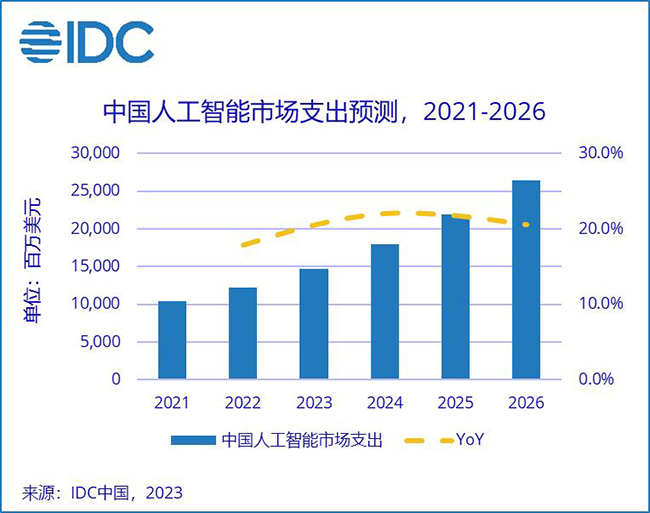
IDC 2023年曾预计,在保持20%年复合增长率长达5年后,到2026年,中国AI市场规模将达到264.4亿美元。同时,包括人工智能(AI)、工业互联网、工业物联网(IIoT)在内的新兴、新型应用场景,对网络的高带宽、低延迟需求,将进一步推进5G、新一代无线网络的发展。他们依托数据中心等核心节点的处理数据,依靠网络连接起更强大的计算资源、更巨量的数据资源,高度依赖高性能、异构网络。
TE Connectivity(泰科电子,以下简称TE)是一家在全球范围之内提供传感器、连接器解决方案的一家全球行业技术企业,其224G产品组合已经过充分验证,符合并引领着关键的行业标准。TE强大的端到端产品组合涉及数据中心的每个部分,从服务器到基础设施,以及介于两者之间的所有设备。TE 与设计合作伙伴一起打造了一个强大的生态系统。
从这个生态系统里的数据传输速率方面来说,如今市场主流正从56G向112G升级,而TE已经可以提供224G产品组合,支持下一代的数据基础设施,并认为112G到224G可能会在今年到明年完成一个切换,两年以后也可能就会实现448G。

数据的传输速率由56G、112G、224G、448G发展的越来越快的时候,连接器变得越来越重要。比如TE的QSFP、QSFP-DD 连接器、壳体和电缆组件,其中的QSFP产品单个可插拔接口中可包含多个数据传输通道,每个通道能够以 10 至 112 Gbps 的速率输数据,因此每个端口支持总计高达 400 Gbps 的带宽;基本上包括SFP连接器在内的所有系列,在满足高速率数据传输的同时,创新采用了散热桥技术,可提高散热能力,优化系统性能。这些器件虽小,但却是连接件及其技术厂商为AI大潮的到来所做出的革新贡献。

另一方面,AI等技术推动下的基础设施快速迭代,对互连性和兼容性也提出了更高要求。TE面向AI和数据中心的224G全链路解决方案和产品组合,不仅仅局限于某个连接器,而是提供端到端整个链路的解决方案,包含从high speed I/O到芯片,从芯片到背板或线缆背板的连接,而且铜缆和光缆连接兼备,应用范围更加广阔。它们在设计时,已经考虑了互连性和兼容性问题,可以帮助大大缩短上市时间并降低整体产品的不确定性,由此各个领域的AI产品或技术能够以惊人的速度迭代更新,不断进步。
此外,TE还为AI数据中心提供诸如液冷在内的新一代供电及散热解决方案,在不扩展数据中心空间情况下,降低PUE、提高计算密度。如TE的high speed I/O产品既可内置散热器,也可集成冷板,从而将热能从模块中传导出去,并保持自身较低的运行温度,也可以显著提高系统的整体效率和可靠性。目前,TE已经有可在200℃的高温环境下稳定工作的10G+速率的高速线缆;而TE的光纤产品,不仅自重轻,而且传输速率大幅提升至200G量级,还能有效地避免数据失真。这些特性对AI计算集群发挥最大算力至关重要。
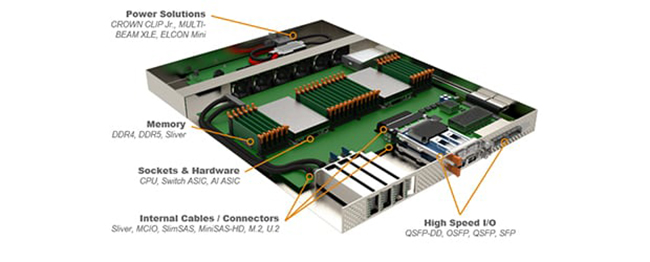
数据连接不仅产生在主机之间、背板之上,连接的建立,甚至从AI芯片开始设计时,就同步开始了。TE就是在AI芯片架构设计、系统架构规划时,便开始深度参与了,其连接件产品需为整个系统优化和芯片设计进行配合。与芯片一起,实现更优化的设计方案,并将这样端到端的连接方案当作参考设计,推荐给AI芯片的用户。芯片设计会对整个数据架构提出要求,TE需要基于速率,把这些要求都考虑到机架设计里面去。

从逻辑上的接口到物理上的连接器,从高速、低延迟到散热,AI时代的TE,正以“All in AI”的策略推进AI芯片与用户之间的连接,携手芯片厂商、所有的互联网客户、软件应用的AI客户等进行深度的配合,为AI系统打通任督二脉,以224G甚至更高的速度,将算力与数据连接起来,推动整个市场的发展。









{kind=link}